Threads have been available since Python 2, but they are often misunderstood and misused because of the limitations and capabilities of threads in Python. When used correctly, they can make your code run faster and more efficiently with very little effort.
In this guide, you will learn about threads, their use cases, and how to use them to run multiple parts of your Python programs concurrently. We'll also go over some alternatives and scenarios where threads may not be a good option.
By the end of this guide, you will be able to develop programs with improved performance by applying multithreading techniques that make better use of your machine resources, such as additional CPU cores.
Table of Contents
- What is a Thread
- Threads and Processes
- Global Interpreter Lock
- Starting Threads
- Waiting for Threads
- Thread Pool
- ThreadPoolExecutor
- Synchronization between Threads
- When to use Threads
- Multithreading vs Multiprocessing
- Why Not Use Asyncio
- Python Multithreading Best Practices
What is a Thread?
Imagine that you have a bunch of tasks that need to be done, like making a sandwich, doing your homework, and playing a video game. You can only do one thing at a time, so you have to decide what to do first.
Now imagine that you have a friend who can help you with some of these tasks. You can both work on different tasks at the same time, which means you can get everything done faster.
This is similar to how threads work in a computer. The computer has a lot of tasks that it needs to do, and it can only do one thing at a time. But it can create little helpers called threads that can work on different tasks at the same time, which makes the computer faster and more efficient.
A thread is like a separate mini-program that runs within the main program. Each thread has its own set of instructions to follow and its own memory space, which means it can perform a specific task independently of the other threads within the same program.
Threads are helpful because they allow a program to do multiple things at the same time. For example, a web browser might use threads to download a file from the internet while also displaying a progress bar and responding to user input.
The operating system (which is the software that runs on a computer and manages the hardware) creates and manages threads. It gives each thread a priority (which determines how much work it gets to do) and makes sure that all the threads get a fair share of the available resources.
A Python thread is just a reference to the native thread provided by the underlying operating system.
Threads and Processes
Every program is a process and has at least one thread that executes instructions for that process. When we run a Python script, it starts a new Python process that runs our code in the main thread.
A thread is a lightweight subprocess, meaning that it runs within the process of a program and shares the same memory space. This allows multiple threads to run concurrently within a single process and can make a program more efficient by allowing different parts of the program to run at the same time.
The Python process will terminate once all (non-background threads) are terminated.
For more information about processes and when to use them instead of threads, see Running Multiple Processes in Python - A Multiprocessing Guide.
Global Interpreter Lock
In Python, the Global Interpreter Lock (aka GIL) is a mechanism that prevents multiple native threads from executing Python code at once.
This lock is necessary because the Python interpreter is not thread-safe, which means that multiple threads can potentially interfere with each other and cause race conditions.
The GIL makes it easy to write simple, thread-safe Python programs, but it can also limit the performance of multithreaded programs, especially those that are heavily CPU-bound. This is because the GIL prevents multiple threads from executing Python code simultaneously, even if the CPU has multiple cores and could potentially run the threads in parallel.
This means that threads in Python are not truly parallel and instead run in a concurrent manner but only one at a time.
So while threads cannot run in parallel, they can run concurrently, which means that more than one task can be in progress at the same time, even if they are not executing at the same time. Once a pending thread can be resumed, Python will switch to executing that thread while the others are still in progress.
Starting Threads
Threads can be started in a number of ways. The most common way to start a thread is to use the threading module in Python. This module provides a number of classes and functions that can be used to start, control, and manage threads.
Given this function which we want to execute in a separate thread from the main program:
def thread_function():
print("Thread function executing")
# Simulate a long task
sleep(1)
We can create a new Thread and specify the function as the target argument in the constructor:
# Create a new thread and start it
thread = Thread(target=thread_function)
thread.start()
The complete example of executing the function in a separate thread:
from threading import Thread
def thread_function():
print("Thread function executing")
# Simulate a long task
sleep(1)
if __name__ == "__main__":
# Create a new thread and start it
thread = Thread(target=thread_function)
thread.start()
# The main program continues concurrently with the new thread
print("Main program continuing to execute")
After the thread is started, the main program continues to execute concurrently with the new thread. The two threads will run concurrently until the main program finishes or until the new thread is stopped or terminated.
Starting threads with arguments
What if we have a function that takes arguments in order to run? Let's update our example to demonstrate how to run a thread with a target function with arguments.
def thread_function(greet, seconds):
print(greet)
# Simulate a long task
sleep(seconds)
We can specify the arguments to the target function in the Thread constructor by setting the args parameter to a tuple of arguments.
# Create a new thread and start it
thread = Thread(target=thread_function, args=("Hello from thread", 3))
thread.start()
Creating daemon threads
The thread constructor also accepts a daemon argument which can be set to True and indicates that we don't need to wait until this thread finishes. These types of threads may be shut down abruptly once the main thread finishes.
# Create a new daemon thread
thread = Thread(target=thread_function, daemon=True)
thread.start()
Daemon threads are typically used for tasks that do not need to be completed before the program exits, such as cleaning up resources or performing periodic maintenance. Also, for tasks that are not related to the main program.
For example, deleting some temp files if you don’t need them anymore may take some time, and we don't need to wait around to know when. Or perhaps some database records to be deleted and also their associated resources. Those can be scheduled in a separate daemon thread.
They are not intended for long-running tasks or tasks that need to be completed before the main program exits.
Waiting for Threads
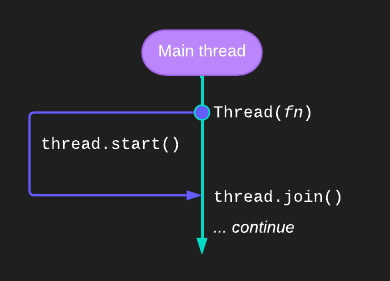
When we need to wait for another thread to finish executing, we can call the join() method. This is not always needed, as the main thread will not exit until the other threads have finished executing or when only daemon threads are left. But when you need to ensure a thread has completed its task, use join().
# Wait for the thread to finish
thread.join()
print("The thread has completed")The main program will pause at this point until the thread finishes execution. Once the thread finishes, the main program continues and executes the statement after the join() call returns.
How to set a thread timeout
It is generally a good practice to use timeouts when joining threads in Python because it allows you to specify a maximum amount of time to wait for the thread to finish. This can be especially useful in situations where you are running multiple threads concurrently, and you want to ensure that your program does not get stuck waiting for a thread that may never complete.
The join() method accepts an optional timeout argument to set the maximum amount of seconds to block when waiting for a thread to finish. Once the timeout is up, the thread will not block anymore, and we can call the is_alive() method to check if a timeout happened - if the thread is still alive, the join() call timed out.
Here's an example:
# Wait 10 seconds for the thread to finish
thread.join(timeout=10)
if thread.is_alive():
print("The thread timed out")
else:
print("The thread has completed")Thread Pool
A thread pool is a group of worker threads that are kept in a pool and are available to perform tasks as needed. Thread pools are used to improve the performance and scalability of programs that perform a lot of tasks concurrently.
So in our example before, instead of having a single friend who can help you with your tasks, imagine that you have a group of friends who can help.
Each of your friends is a worker thread, and they are all part of your thread pool. When you have a task that needs to be done, you can ask one of your friends to help you with it. Once they finish the task, they go back to the thread pool and wait for the next task.
Using a thread pool can help to improve the performance of a program because the threads can be reused, which means that the program doesn't have to create a new thread every time it needs to perform a task. This can save time and resources.
Let's see an example of how to use a ThreadPool:
from multiprocessing.pool import ThreadPool
def task_function(x):
print(f"Calculating square of {x} in thread.")
return x**2
if __name__ == "__main__"
with ThreadPool() as pool:
numbers = [1, 3, 5, 8, 13]
result = pool.map(task_function, numbers)
print(result)In this example, a ThreadPool is used to create and start threads to run the target function for each number in the numbers list.
We can specify an argument to limit how many worker threads to use. If we leave this out, Python creates as many threads as the number of processors in the machine, which is obtained by calling os.cpu_count().
Let's visualize a single thread running a task vs using multiple threads. Note how using more threads brings execution time down:
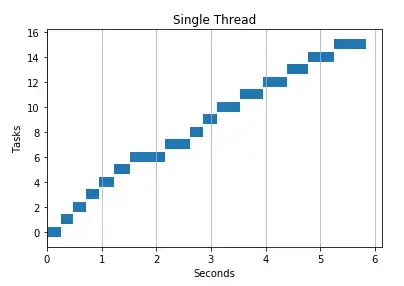
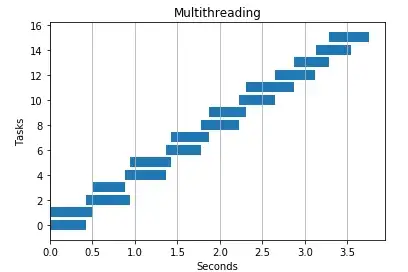
Thread pools are no more than a wrapper around the threading module, and in general, we should prefer to use the ThreadPoolExecutor, which has a simpler interface and better compatibility with many other libraries, including asyncio.
ThreadPoolExecutor
ThreadPoolExecutor is a class that can be used to create and manage a thread pool. It is part of the concurrent.futures module, which provides a high-level interface for executing tasks concurrently using threads or processes.
A ThreadPoolExecutor manages a fixed number of worker threads and a task queue. When a task is submitted to the executor, it is placed in the task queue, and a worker thread is assigned to perform the task when one becomes available. The worker thread then executes the task and returns the result (if any) to the caller.
A ThreadPoolExecutor differs from a simple thread pool in that it provides a more feature-rich interface for managing and executing tasks concurrently. For example, it allows you to:
- Submit tasks asynchronously using
Futureobjects, which can be used to track the progress of the task and retrieve the result when it is completed. - Set a maximum number of worker threads and a maximum size for the task queue to control the level of concurrency.
- Handle exceptions and cancel tasks that have not yet started.
Here is a simple example of how to use the ThreadPoolExecutor class to execute a task concurrently in Python:
from concurrent.futures import ThreadPoolExecutor
def task_function(n):
print(f"Task {n} running")
if __name__ == "__main__":
# Create a ThreadPoolExecutor with 2 worker threads
with ThreadPoolExecutor(max_workers=2) as executor:
# Submit a task to the executor
future = executor.submit(task_function, 1)
# The main program continues to execute concurrently with the task
print("Main program continuing to execute")
In this example, the task_function is a simple function that prints a message to the console. The ThreadPoolExecutor is created with a maximum of 2 worker threads, which means that at most 2 tasks can be executed concurrently.
Since Python 3.5, if we don't specify the number of max_workers, it will default to the number of processors on the machine multiplied by 5.
To submit a task to the executor, you can use the submit method and pass in the function and any arguments that the function requires. This returns a Future object, which represents the result of the task and can be used to track the progress of the task and retrieve the result when it is completed.
We can also use a ThreadPoolExecutor as a simplified version of the ThreadPool we discussed earlier:
from time import sleep
from random import random
from concurrent.futures import ThreadPoolExecutor
def target_function(name):
# sleep for less than a second
sleep(random())
return name
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# execute tasks concurrently and process results in order
for result in executor.map(target_function, range(10)):
# retrieve the result
print(result)You may be interested in the results of the ThreadPoolExecutor as they become available instead of once all the tasks have been completed. Note that the order in which tasks are completed is not guaranteed.
from concurrent.futures import as_completed
...
# start the thread pool
with ThreadPoolExecutor(10) as executor:
# submit tasks and collect futures
futures = [executor.submit(target_function, i) for i in range(10)]
# process task results as they are available
for future in as_completed(futures):
# retrieve the result
print(future.result())What Are Futures
A Future object acts as a placeholder for the result of a task that has not yet completed. It allows you to track the progress of the task and retrieve the result when it is completed.
It is also sometimes called a promise or a delay. It provides a context for the result of a task that may or may not be executing and a way of getting a result once it is available.
In Python, the Future object is returned from an Executor, such as the ThreadPoolExecutor, when calling the submit() method to dispatch a task to be executed asynchronously.
A Future also provides access to the result of the task via the result() method. If an exception was raised while executing the task, it will be re-raised when calling the result() method or can be accessed via the exception() method.
result(): Access the result from running the task.exception(): Access any exception raised while running the task.
Both the result() and exception() methods allow a timeout to be specified as an argument, which is the number of seconds to wait for a return value if the task is not yet complete. If the timeout expires, then a TimeoutError will be raised.
Synchronization between threads
When multiple threads are running concurrently, it is important to ensure that they do not interfere with each other. This is done through synchronization, which is the process of ensuring that all threads are in sync and are accessing the same data.
Consider a program that has a shared counter variable that is incremented by multiple threads. If two threads try to increment the counter simultaneously, it is possible that the final value of the counter will be incorrect because the threads may interfere with each other's updates. This is called a race condition.
A race condition is a concurrency failure case when two threads run the same code and access or update the same resource (e.g. data variables, stream, etc.), leaving the resource in an unknown and inconsistent state.
Race conditions often result in unexpected behavior of a program and/or corrupt data.
Try running this example many times, and you will encounter a race condition:
import threading
counter = 0
def increment_counter():
global counter
counter += 1
# Create two threads that try to increment the counter simultaneously
t1 = threading.Thread(target=increment_counter)
t2 = threading.Thread(target=increment_counter)
# Start the threads
t1.start()
t2.start()
# Wait for the threads to finish
t1.join()
t2.join()
# Print the final value of the counter
print(counter)Using threading.local
A key difference between processes and threads is that processes have their own separate memory space, while threads share the memory space of the process that created them. This means that threads can communicate with each other more easily, but it also means that if one thread modifies the shared memory, it can affect the other threads in the process.
One way to make sure threads don't interfere with each other is to separate the data they operate on, so other threads can't access them. We can do that using the threading.local class which provides a dictionary-like object that is specific to a thread, and each thread gets its own separate copy of the values stored in the threading.local object.
import threading
# Create a thread-local data object
local_data = threading.local()
def process_request(request):
# Store the request data in the thread-local data object
local_data.request = request
# Do some processing with the request data
# ...
# Start a new thread and process a request
t = threading.Thread(target=process_request, args=(request,))
t.start()
In this example, the process_request function stores the request data in the local_data object, which is specific to the thread that is executing the function. This means that the request data will not be shared with any other threads, and each thread can have its own separate copy of the request data.
We can also separate the data between threads using threading and queue:
import threading
import queue
def worker(q):
while True:
item = q.get()
if item is None:
break
# process the item
print(item)
q.task_done()
q = queue.Queue()
# add items to the queue
for item in range(100):
q.put(item)
# create worker threads
threads = []
for i in range(4):
t = threading.Thread(target=worker, args=(q,))
t.start()
threads.append(t)
# wait for all tasks to be completed
q.join()
for t in threads:
t.join()
Locks
A (mutually exclusive) lock can be used to ensure that only one thread at a time executes a critical section of code at a time, while all other threads trying to execute the same code must wait until the currently executing thread is finished with the critical section and releases the lock.
To avoid a race condition in Python using a lock, we can use the threading.Lock class to create a lock object, and then use the acquire and release methods of the lock to control access to the shared resource.
Here is an example of how we can use a lock to avoid a race condition in Python:
from threading import Thread
counter = 0
lock = threading.Lock()
def increment_counter():
global counter
with lock:
# Critical section executed by a single thread at a time
counter += 1
# Create two threads that try to increment the counter simultaneously
t1 = Thread(target=increment_counter)
t2 = Thread(target=increment_counter)
# Start the threads
t1.start()
t2.start()
# Wait for the threads to finish
t1.join()
t2.join()
# Print the final value of the counter
print(counter)
In this example, the increment_counter function acquires the lock before accessing and modifying the shared counter variable. This ensures that only one thread can execute the code inside the with block at a time, which prevents the race condition from occurring. As a result, the final value of the counter will always be 2, regardless of the order in which the threads execute.
Something to keep in mind is that we must ensure the holder releases any acquired locks. Otherwise, other threads may wait indefinitely for access, and our program may never finish. This is called a deadlock.
When to Use Threads
As we saw earlier, the Python interpreter prevents more than one thread from executing bytecode at the same time.
This is achieved using a lock called the Global Interpreter Lock or GIL, as we learned in the previous section.
To bypass the GIL and take full advantage of multiple CPU cores in your Python program, you may want to consider using a different concurrency framework like multiprocessing and also concurrent.futures. These frameworks allow you to create multiple processes, each with its own Python interpreter and GIL, which can run in parallel on separate CPU cores.
There are other times when the lock is released by the interpreter, and we can achieve parallel execution of our concurrent code in Python.
Examples of when the lock is released include:
- When a thread is performing blocking IO.
- When a thread is executing C code and explicitly releases the lock.
This makes threads good candidates for IO-bound tasks.
An IO-bound task is a type of task that involves reading from or writing to a device, file, or socket connection. These tasks involve input and output (IO), and the speed of these operations is bound by the device, hard drive, or network connection. This is why these tasks are referred to as IO-bound.
A thread performing an IO operation will block for the duration of the operation. While blocked, this signals to the operating system that a thread can be suspended and another thread can execute, called a context switch.
Additionally, the Python interpreter will release the GIL when performing blocking IO operations, allowing other threads within the Python process to execute.
This is why blocking IO operations are an excellent use case for using threads in Python.
Let's look at practical examples of blocking IO operations in real applications:
Reading or writing a file from the hard drive
# Open the file for writing
def write_file():
with open('filename.txt', 'w') as f:
# Write some text to file, could take long...
f.write('Local data saved.')
Printing a document
If you want to print the output to a specific device, such as a printer, you can use the print() function in combination with a library that provides printing functionality. For example, you can use the pycups library to print to a CUPS (Common Unix Printing System) printer or the win32print library to print to a printer on a Windows operating system.
import cups
# Connect to the local CUPS server
conn = cups.Connection()
# Get a list of available printers
printers = conn.getPrinters()
# Print a document to the default printer
conn.printFile(printers.keys()[0], '/path/to/file.pdf', 'Title', {})
Downloading or uploading a file
import requests
# URL of the file to download
url = 'https://www.example.com/file.zip'
def download_url(url):
# Send an HTTP GET request to the URL
response = requests.get(url)
# Check for a successful response
if response.status_code == 200:
# Save the content of the response to a file
with open('file.zip', 'wb') as f:
# Writing to file here is blocking
f.write(response.content)
This will download the file at the specified URL and save it to the current working directory with the name file.zip.
Working with APIs
Here is an example of how you can use the Python requests library to query a real-world API:
import requests
def openweather_api(city="London", country_code="UK"):
# Set the API endpoint and API key
api_endpoint = "https://api.openweathermap.org/data/2.5/weather"
# Set the parameters for the API request
params = {
"q": f"{city},{country_code}",
"appid": "YOUR_API_KEY_HERE",
}
# The request to the API endpoint blocks until we get a response
response = requests.get(api_endpoint, params=params)
# Check the status code of the response to check if successful
if response.status_code == 200:
# If the request was successful, get the data from the response
data = response.json()
# You can now process the data as needed
print(data)
else:
print("Request failed with status code:", response.status_code)
print("Error message:", response.text)
Connecting to a database
import sqlite3
with sqlite3.connect("database.db") as conn:
# Create a cursor
cursor = conn.cursor()
# The execute blocks while connecting to the database
cursor.execute("CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER)")
data=('Alice', 25)
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", data)
Taking a photo or recording a video.
To take a photo or record a video using Python, you will need to use a library or module that provides access to the camera or video capture functionality of your system. One option is the cv2 (OpenCV) library:
import cv2
# Open the camera
camera = cv2.VideoCapture(0)
def take_photo(filename='photo.jpg')
ret, frame = camera.read()
if ret:
# Save the photo to a file
cv2.imwrite(filename, frame)
def take_video(filename='video.mp4', width=640, height=480)
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
out = cv2.VideoWriter(filename, fourcc, 30.0, (width,height))
while True:
# Capture a frame from the camera
ret, frame = camera.read()
if not ret:
break
# Write the frame to the video file
out.write(frame)
# Show the frame
cv2.imshow("Webcam", frame)
# Release the camera and video writer
camera.release()
out.release()
cv2.destroyAllWindows()Multithreading vs Multiprocessing
Threads and Processes are quite different, and choosing one over the other is intentional.
A Python program is a process that has a main thread. You can create many additional threads in a Python process. You can also fork or spawn many Python processes, each of which will have one thread and may spawn additional threads.
More broadly, threads are lightweight and can share memory (data and variables) within a process, whereas processes are heavyweight and require more overhead and impose more limits on sharing memory (data and variables).
Typically, processes are used for CPU-bound tasks, and threads are used for IO-bound tasks, and this is a good heuristic, but this is not always the case. In the real world, we may need to write programs that contain a mix of both IO-bound tasks and CPU-bound tasks.
In this case, we should experiment with using threading for the IO-bound tasks of our programs and processes or multiprocessing too for the CPU-bound parts. Perhaps try it and see.
You can learn all about multiprocessing in this guide:

Why Not Use Asyncio
Asyncio is a newer alternative to using threads introduced in Python 3.4 and is probably worth investigating as a replacement for multithreading.
Asyncio is designed to support large numbers of IO operations, perhaps thousands to tens of thousands, all within a single Thread.
If you are writing a new program from scratch, you may be better off using asyncio instead of threads.
On the other hand, if you are working with an existing codebase containing legacy code or targeting an older version of Python, your best bet is to use threads.
Simply put, threads should be considered only when working with legacy code if you need to speed up some IO-bound tasks in an established code base.
You can learn all about asyncio in python with our guide:

Python Multithreading Best Practices
Now that we know threads work and how to use them let’s review some best practices to consider when bringing threads into our Python programs.
Best practices to keep in mind when using threads in Python:
- Use Context Managers
- Use Timeouts When Waiting
- Use Locks to Prevent Race Conditions
- Consider Using Asyncio
References
Did you find this guide helpful?
If so, I'd love to know. Please share what you learned in the comments below.
How are you using threads in your programs?
I’d love to hear about it, too. Please let me know in the comments.
Do you have any questions?
Leave your question in a comment below, and I'll answer it with my best advice.

